Last Time On 36 Chambers
Yesterday, I wrote a large number of words to give us some sample data that we could use today.
To give you a quick reminder of the problem we’re trying to solve, we can have multiple concurrent work items processing for a customer, but we want to limit that number to 2. The development team put in a check to throttle customers and want us to write a query to ensure that they wrote their check correctly.
*Narrator’s voice*: They didn’t.
Meanwhile, Back At The Wrench
Because this is a difficult problem, I immediately looked for an Itzik Ben-Gan solution and found one. Here’s my take on his solution, but definitely read his article.
Based on yesterday’s work, we can generate an arbitrary number of values which approximate a normal distribution, so we’re going to build 5 million rows worth of start and stop times for customers. Here’s the code we will use:
DROP TABLE IF EXISTS #WorkItems;
CREATE TABLE #WorkItems
(
WorkItemID INT NOT NULL PRIMARY KEY CLUSTERED,
CustomerID INT NOT NULL,
WorkItemStart DATETIME2(0) NOT NULL,
WorkItemEnd DATETIME2(0) NULL
);
DECLARE
@NumberOfRecords INT = 5000000,
@NumberOfCustomers INT = 150,
@StartDate DATETIME2(0) = '2018-12-18 15:00:00',
@MeanRunLengthInSeconds DECIMAL(5,2) = 90.0,
@StdDevRunLengthInSeconds DECIMAL(5,2) = 18.8,
@MeanLengthBetweenRunsInSeconds DECIMAL(5,2) = 128.0,
@StdDevLengthBetweenRunsInSeconds DECIMAL(5,2) = 42.3,
@Precision INT = 1;
WITH
L0 AS(SELECT 1 AS c UNION ALL SELECT 1),
L1 AS(SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS(SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS(SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS(SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS(SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY (SELECT 0)) AS n FROM L5),
Vals AS
(
SELECT TOP (@NumberOfRecords)
n,
r.CustomerID,
s.NumberOfSecondsToRun,
s.NumberOfSecondsBeforeNextRunBegins
FROM Nums
CROSS APPLY (
SELECT
RAND(CHECKSUM(NEWID())) AS rand1,
RAND(CHECKSUM(NEWID())) AS rand2,
CAST(@NumberOfCustomers * RAND(CHECKSUM(NEWID())) AS INT) + 1 AS CustomerID
) r
CROSS APPLY
(
SELECT
ROUND((SQRT(-2.0 * LOG(r.rand1)) * COS(2 * PI() * r.rand2)) * @StdDevRunLengthInSeconds, @Precision) + @MeanRunLengthInSeconds AS NumberOfSecondsToRun,
ROUND((SQRT(-2.0 * LOG(r.rand1)) * SIN(2 * PI() * r.rand2)) * @StdDevLengthBetweenRunsInSeconds, @Precision) + @MeanLengthBetweenRunsInSeconds AS NumberOfSecondsBeforeNextRunBegins
) s
),
records AS
(
SELECT
v.n AS WorkItemID,
v.CustomerID,
v.NumberOfSecondsToRun,
v.NumberOfSecondsBeforeNextRunBegins,
SUM(v.NumberOfSecondsBeforeNextRunBegins) OVER (PARTITION BY v.CustomerID ORDER BY v.n ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) - v.NumberOfSecondsBeforeNextRunBegins AS TotalNumberOfSeconds
FROM vals v
)
INSERT INTO #WorkItems
(
WorkItemID,
CustomerID,
WorkItemStart,
WorkItemEnd
)
SELECT
r.WorkItemID,
r.CustomerID,
s.WorkItemStart,
DATEADD(SECOND, r.NumberOfSecondsToRun, s.WorkItemStart) AS WorkItemEnd
FROM records r
CROSS APPLY
(
SELECT
DATEADD(SECOND, r.TotalNumberOfSeconds, @StartDate) AS WorkItemStart
) s;On the ridiculously overpowered server that I’m abusing to do this blog post, it took about 32 seconds to generate 5 million rows. We are generating data for 150 customers using a uniform distribution, so we’d expect somewhere around 33,333 records per customer. In my sample, customer work item counts range from 32,770 to 33,747 so there’s a little bit of variance, but not much.
Building A Solution: A Single Customer
Just like before, we’re going to squeeze a few hundred more words out of this post build up a query step by step. Our first step will be to get the starting times and ending times for each of our selected customer’s work items. Each starting point and each ending point will take a row, so we’ll use UNION ALL to unpivot this data.
DECLARE
@CustomerID INT = 1;
SELECT
wi.CustomerID,
wi.WorkItemStart AS TimeUTC,
1 AS IsStartingPoint,
ROW_NUMBER() OVER (ORDER BY wi.WorkItemStart) AS StartOrdinal
FROM #WorkItems wi
WHERE
wi.CustomerID = @CustomerID
UNION ALL
SELECT
wi.CustomerID,
wi.WorkItemEnd AS TimeUTC,
0 AS IsStartingPoint,
NULL AS StartOrdinal
FROM #WorkItems wi
WHERE
wi.CustomerID = @CustomerIDFor my data set, I get something like the following:

As a quick note, the start times are all in order but the end times are arbitrarily ordered, as ordering won’t matter where we’re going.
Then, we want to build out step two, where we add an ordering based on time for each of the start and stop points:
DECLARE
@CustomerID INT = 1;
WITH StartStopPoints AS
(
SELECT
wi.CustomerID,
wi.WorkItemStart AS TimeUTC,
1 AS IsStartingPoint,
ROW_NUMBER() OVER (ORDER BY wi.WorkItemStart) AS StartOrdinal
FROM #WorkItems wi
WHERE
wi.CustomerID = @CustomerID
UNION ALL
SELECT
wi.CustomerID,
wi.WorkItemEnd AS TimeUTC,
0 AS IsStartingPoint,
NULL AS StartOrdinal
FROM #WorkItems wi
WHERE
wi.CustomerID = @CustomerID
)
SELECT
s.CustomerID,
s.TimeUTC,
s.IsStartingPoint,
s.StartOrdinal,
ROW_NUMBER() OVER (ORDER BY s.TimeUTC, s.IsStartingPoint) AS StartOrEndOrdinal
FROM StartStopPoints s;Running this gives us the following results for my data:
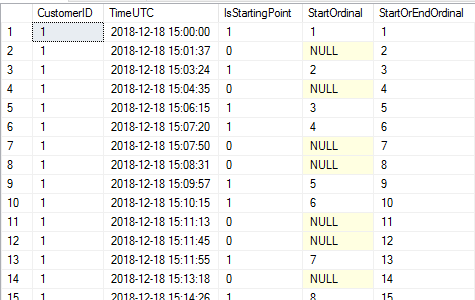
You can probably see by this point how the pieces are coming together: each time frame has a starting point and an ending point. If there were no overlap at all, we’d see in the fourth column a number followed by a NULL, followed by a number followed by a NULL, etc. But we clearly don’t see that: we see work item ordinals 3 and 4 share some overlap: item 3 started at 3:06:15 PM and ended after item 4’s start of 3:07:20 PM. This means that those two overlapped to some extent. Then we see two NULL values, which means they both ended before 5 began. So far so good for our developers!
The final calculation looks like this:
DECLARE
@CustomerID INT = 1;
WITH StartStopPoints AS
(
SELECT
wi.CustomerID,
wi.WorkItemStart AS TimeUTC,
1 AS IsStartingPoint,
ROW_NUMBER() OVER (ORDER BY wi.WorkItemStart) AS StartOrdinal
FROM #WorkItems wi
WHERE
wi.CustomerID = @CustomerID
UNION ALL
SELECT
wi.CustomerID,
wi.WorkItemEnd AS TimeUTC,
0 AS IsStartingPoint,
NULL AS StartOrdinal
FROM #WorkItems wi
WHERE
wi.CustomerID = @CustomerID
),
StartStopOrder AS
(
SELECT
s.CustomerID,
s.TimeUTC,
s.IsStartingPoint,
s.StartOrdinal,
ROW_NUMBER() OVER (ORDER BY s.TimeUTC, s.IsStartingPoint) AS StartOrEndOrdinal
FROM StartStopPoints s
)
SELECT
MAX(2 * s.StartOrdinal - s.StartOrEndOrdinal) AS MaxConcurrentWorkItems
FROM StartStopOrder s
WHERE
s.IsStartingPoint = 1;Because we know that each start (probably) has an end, we need to multiply StartOrdinal by 2. Then, we want to compare the result of that calculation to StartOrEndOrdinal. If you go back up to the previous image, you can see how this gives us 1 concurrent item for the first three work items, but as soon as we add in work item 4, 2*4-6 = 2, so we now have two concurrent work items. By the way, this ran in about 26ms for me and took 182 reads if you use an index that I create below. But don’t skip that far ahead yet; we have more to do!
Voila. Or viola, whichever.
But wait, there’s more!
Where Am I Overlapping The Most?
Naturally, if I know that my max overlap window is 3, I’d be curious about when that happened—maybe I can correlate it with logs and figure out which intern to blame (protip: have interns in different time zones so you always have a likely culprit).
Getting the results is easy, for some definition of “easy” which doesn’t really fit with the normal definition of “easy.”
First, we will create a temp table called #MaxConcurrentItems. This will hold all of the work items which are equal to the max concurrent item count.
DROP TABLE IF EXISTS #MaxConcurrentItems;
CREATE TABLE #MaxConcurrentItems
(
WorkItemID INT PRIMARY KEY CLUSTERED,
CustomerID INT,
MaxConcurrentWorkItems INT
);
DECLARE
@CustomerID INT = 1,
@MaxConcurrentWorkItems INT = 0;
WITH StartStopPoints AS
(
SELECT
wi.WorkItemID,
wi.CustomerID,
wi.WorkItemStart AS TimeUTC,
1 AS IsStartingPoint,
ROW_NUMBER() OVER (ORDER BY wi.WorkItemStart) AS StartOrdinal
FROM #WorkItems wi
WHERE
wi.CustomerID = @CustomerID
UNION ALL
SELECT
wi.WorkItemID,
wi.CustomerID,
wi.WorkItemEnd AS TimeUTC,
0 AS IsStartingPoint,
NULL AS StartOrdinal
FROM #WorkItems wi
WHERE
wi.CustomerID = @CustomerID
),
StartStopOrder AS
(
SELECT
s.WorkItemID,
s.CustomerID,
s.TimeUTC,
s.IsStartingPoint,
s.StartOrdinal,
ROW_NUMBER() OVER (ORDER BY s.TimeUTC, s.IsStartingPoint) AS StartOrEndOrdinal
FROM StartStopPoints s
),
MaxConcurrency AS
(
SELECT
MAX(2 * s.StartOrdinal - s.StartOrEndOrdinal) AS MaxConcurrentWorkItems
FROM StartStopOrder s
WHERE
s.IsStartingPoint = 1
)
INSERT INTO #MaxConcurrentItems
(
WorkItemID,
CustomerID,
MaxConcurrentWorkItems
)
SELECT
s.WorkItemID,
s.CustomerID,
M.MaxConcurrentWorkItems
FROM StartStopOrder s
CROSS JOIN MaxConcurrency m
WHERE
2 * s.StartOrdinal - s.StartOrEndOrdinal = m.MaxConcurrentWorkItems;So let’s explain this step by step:
StartStopPointsandStartStopOrderare the same as before.- Instead of returning
MaxConcurrentWorkItems, we’re dropping that into a CTE calledMaxConcurrency. - Once we have the max level of concurrency, we want to go back to
StartStopOrderand get all of the cases where the number of concurrent work items is equal to the maximum number of concurrent work items. We insert this into#MaxConcurrentWorkItems.
From there, I populate @MaxConcurrentWorkItems with the max value we retrieve above (so I don’t need to calculate it again) and I want to get the record which pushed us to the max level of concurrency as well as all of the prior records in that grouping. We already know a technique for turning one row into multiple rows: a tally table.
I do need to go back and get the start ordinals for each row in #WorkItems for that customer ID; that way, I can join against the tally table and get prior records, defined where MaxRow.StartOrdinal = WorkItem.StartOrdinal + n - 1. The -1 at the end is because our tally table starts from 1 instead of 0; if yours has a 0 value, then you can change the inequality operation in the WHERE clause below and include just the n rows without any subtraction involved.
Here is the solution in all its glory:
DROP TABLE IF EXISTS #MaxConcurrentItems;
CREATE TABLE #MaxConcurrentItems
(
WorkItemID INT PRIMARY KEY CLUSTERED,
CustomerID INT,
MaxConcurrentWorkItems INT
);
DECLARE
@CustomerID INT = 1,
@MaxConcurrentWorkItems INT = 0;
WITH StartStopPoints AS
(
SELECT
wi.WorkItemID,
wi.CustomerID,
wi.WorkItemStart AS TimeUTC,
1 AS IsStartingPoint,
ROW_NUMBER() OVER (ORDER BY wi.WorkItemStart) AS StartOrdinal
FROM #WorkItems wi
WHERE
wi.CustomerID = @CustomerID
UNION ALL
SELECT
wi.WorkItemID,
wi.CustomerID,
wi.WorkItemEnd AS TimeUTC,
0 AS IsStartingPoint,
NULL AS StartOrdinal
FROM #WorkItems wi
WHERE
wi.CustomerID = @CustomerID
),
StartStopOrder AS
(
SELECT
s.WorkItemID,
s.CustomerID,
s.TimeUTC,
s.IsStartingPoint,
s.StartOrdinal,
ROW_NUMBER() OVER (ORDER BY s.TimeUTC, s.IsStartingPoint) AS StartOrEndOrdinal
FROM StartStopPoints s
),
MaxConcurrency AS
(
SELECT
MAX(2 * s.StartOrdinal - s.StartOrEndOrdinal) AS MaxConcurrentWorkItems
FROM StartStopOrder s
WHERE
s.IsStartingPoint = 1
)
INSERT INTO #MaxConcurrentItems
(
WorkItemID,
CustomerID,
MaxConcurrentWorkItems
)
SELECT
s.WorkItemID,
s.CustomerID,
M.MaxConcurrentWorkItems
FROM StartStopOrder s
CROSS JOIN MaxConcurrency m
WHERE
2 * s.StartOrdinal - s.StartOrEndOrdinal = m.MaxConcurrentWorkItems;
SELECT
@MaxConcurrentWorkItems = MAX(mci.MaxConcurrentWorkItems)
FROM #MaxConcurrentItems mci;
WITH L0 AS(SELECT 1 AS c UNION ALL SELECT 1),
L1 AS(SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS(SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY (SELECT 0)) AS n FROM L2),
WorkItems AS
(
SELECT
wi.WorkItemID,
wi.CustomerID,
wi.WorkItemStart,
wi.WorkItemEnd,
ROW_NUMBER() OVER (ORDER BY wi.WorkItemStart) AS StartOrdinal
FROM #WorkItems wi
WHERE
wi.CustomerID = @CustomerID
),
MaxWorkItems AS
(
SELECT
wi.WorkItemID,
wi.CustomerID,
wi.WorkItemStart,
wi.WorkItemEnd,
wi.StartOrdinal,
ROW_NUMBER() OVER (ORDER BY mci.WorkItemID) AS WorkItemGrouping
FROM #MaxConcurrentItems mci
INNER JOIN WorkItems wi
ON mci.WorkItemID = wi.WorkItemID
)
SELECT
wi.WorkItemID,
wi.CustomerID,
wi.WorkItemStart,
wi.WorkItemEnd,
M.WorkItemGrouping
FROM MaxWorkItems M
CROSS JOIN Nums n
INNER JOIN WorkItems wi
ON M.StartOrdinal = (wi.StartOrdinal + n.n - 1)
WHERE
n.n <= @MaxConcurrentWorkItems
ORDER BY
wi.WorkItemID ASC;And here’s the results for customer 1:
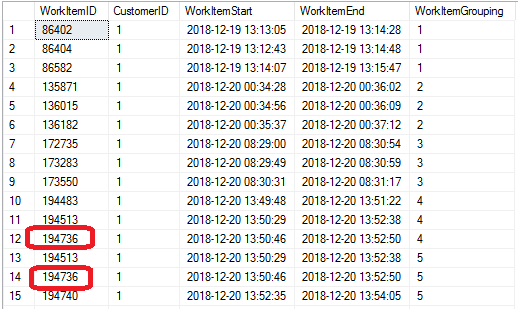
For bonus wackiness, the same work item can be in multiple groupings. That makes sense: we can see from this mess that 194483 finished at 13:51:22 and 197740 began at 13:52:35, but 194736 and 194513 were both active during that entire stretch, so our pattern of active work items was 1-2-3-2-3.
So we get our results, but at what cost? Here’s the execution plan for the whole thing:
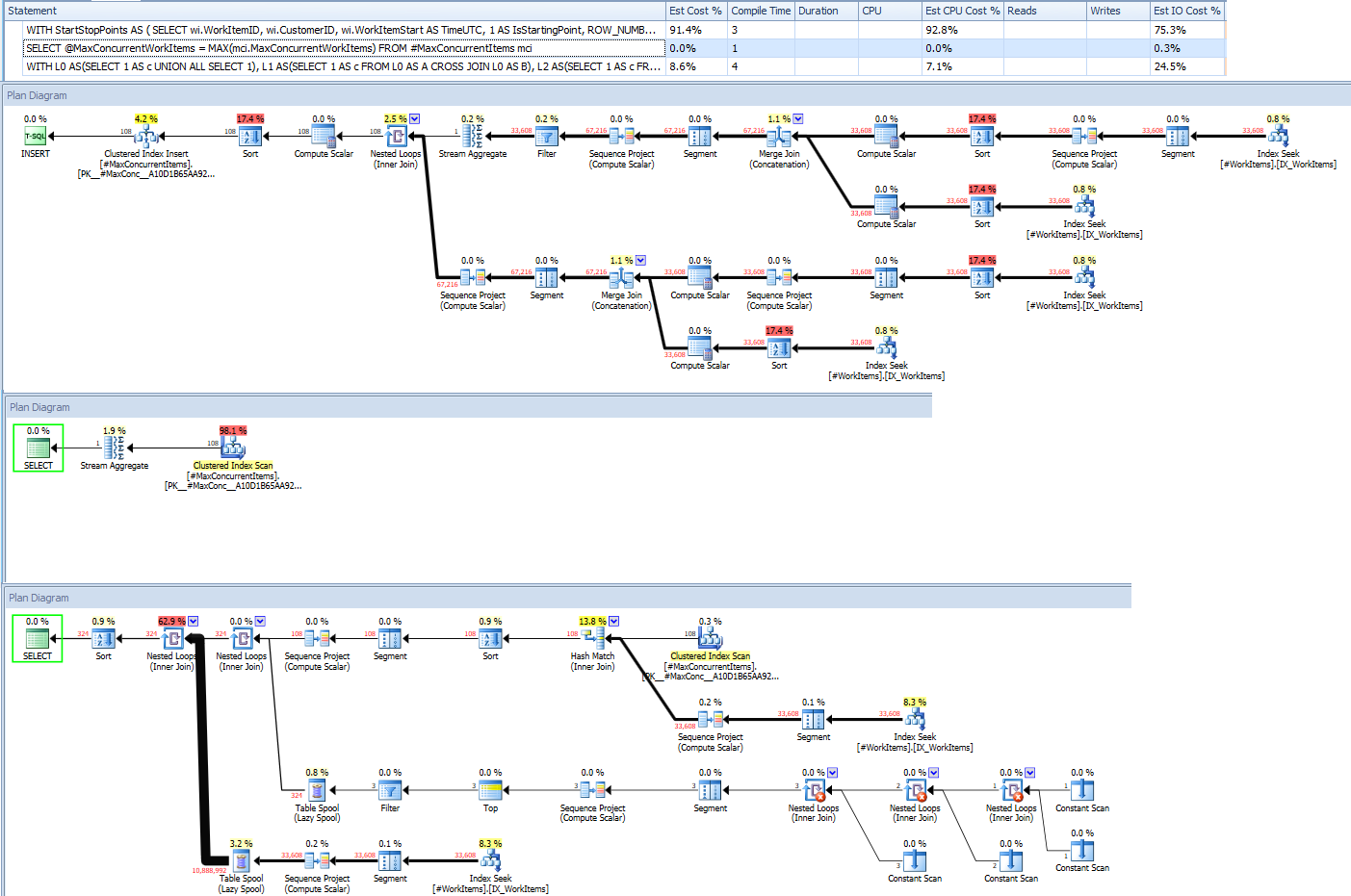
Also blame the interns for a couple of awful queries.
Despite this awful query plan, this ran in about 1.5 seconds, but had a worktable with 129K reads. I could definitely tune this query by saving my slice of work items with ordinals off in its own temp table and querying that…but my editor says I have to wrap up this section now, so let’s jump straight to the moral of the story.
The moral of the story? I already told you: have lots of interns so you always have someone to blame.
What Is My Overlap Per Customer?
Now I’d like to see what the overlap is across all of my 150 customers. Here goes:
WITH StartStopPoints AS
(
SELECT
wi.CustomerID,
wi.WorkItemStart AS TimeUTC,
1 AS IsStartingPoint,
ROW_NUMBER() OVER (PARTITION BY wi.CustomerID ORDER BY wi.WorkItemStart) AS StartOrdinal
FROM #WorkItems wi
UNION ALL
SELECT
wi.CustomerID,
wi.WorkItemEnd AS TimeUTC,
0 AS IsStartingPoint,
NULL AS StartOrdinal
FROM #WorkItems wi
),
StartStopOrder AS
(
SELECT
s.CustomerID,
s.TimeUTC,
s.IsStartingPoint,
s.StartOrdinal,
ROW_NUMBER() OVER (PARTITION BY s.CustomerID ORDER BY s.TimeUTC, s.IsStartingPoint) AS StartOrEndOrdinal
FROM StartStopPoints s
)
SELECT
s.CustomerID,
MAX(2 * s.StartOrdinal - s.StartOrEndOrdinal) AS MaxConcurrentWorkItems
FROM StartStopOrder s
WHERE
s.IsStartingPoint = 1
GROUP BY
s.CustomerID
ORDER BY
MaxConcurrentWorkItems DESC,
CustomerID ASC;At our worst, we have 5 concurrent work items for customer 139:

This query took several seconds to run, so let’s check out the execution plan:

If thick arrows are your idea of a good time, this is going great.
We have two separate scans of the WorkItems table, and we can see the Segment-Sequence combo which represents a window function show up twice. The biggest pain point is a major Sort operation which in my case spilled at level 1.
So let’s create an index:
CREATE NONCLUSTERED INDEX [IX_WorkItems] ON #WorkItems
(
CustomerID,
WorkItemStart,
WorkItemEnd
) WITH(DATA_COMPRESSION = PAGE);As a quick note, there’s nothing here which prevents users from running two files at the same time, so I can’t make this a unique index.
Doing this didn’t change the execution plan much, but did change IO from 53,368 reads to 26,233 reads and reduced overall execution time on this server from 6925ms (17,406ms CPU time) down to 3650ms (8203ms CPU time) so that’s not awful.
Wrapping Up
Over the course of this two-post series, we have generated a lot of artificial data in order to find overlapping time ranges. Along the way, we learned many important things, such as having plenty of cannon fodder interns around.

3 thoughts on “Finding Max Concurrent Operations With T-SQL (Part 2)”