This is part six in a series on low-code machine learning with Azure ML.
Last Time on 36 Chambers
In the prior episode of this series, we built a real-time endpoint, showed how to call it, and saw how to make some minor changes to a real-time inference pipeline.
Today, we’re going to show off bulk processing.
Cheaper to Buy in Bulk
Let’s navigate to the Designer option of the Author menu and choose the training pipeline.

Inside the training pipeline, we want to create a new Batch inference pipeline.

This generates a new pipeline which looks just like the real-time inference pipeline. Because I don’t want to have us waste time have a learning experience a second time, let’s add a Select Columns in Dataset component from the Data Transformation menu, include everything but Species in that component, and hook it up. If you forget how to do this, refer back to the prior post. Also, remove the Evaluate Model component, as we don’t need that where we’re going.
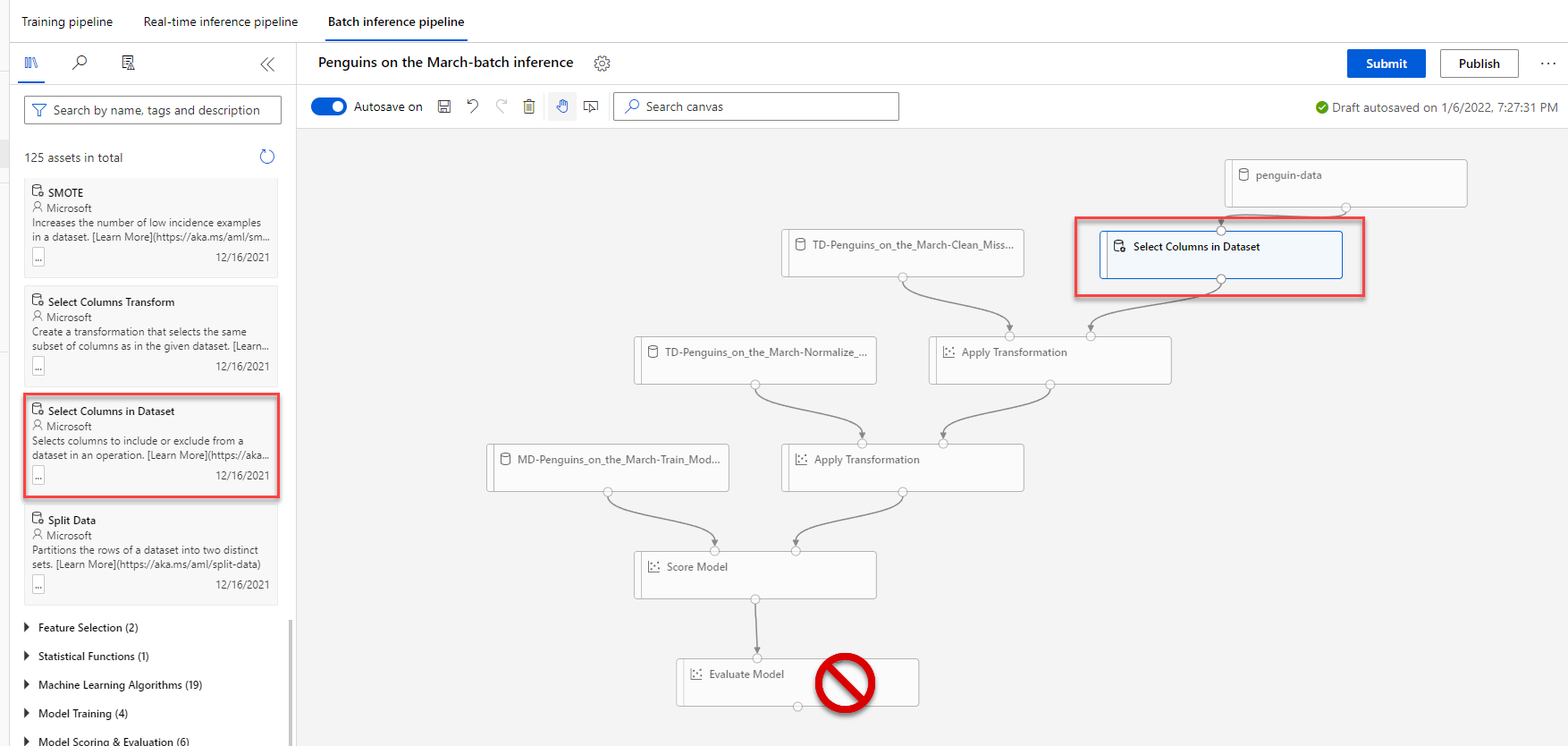
Finally, select the penguin-data component and choose Set as pipeline parameter. That will allow us to pass in the location of a dataset as a parameter.

Once you have all of this in place, select Submit to submit the job. You might see an error message indicating that a compute target is invalid:

In that case, select the error message and change the compute target to a proper compute cluster.

Select Submit one more time and you should be able to re-use an experiment from earlier.

We’ll need to wait for the inference pipeline process to run. Kick back, relax, and be glad you aren’t on a time crunch here. Once everything’s done, select Publish to continue to the next step. We’re going to create a new endpoint here.
If you see a message like the following, it indicates that you haven’t set up a pipeline parameter, and you’ll want to go back and check that box on the penguin-data component:

Once you have all of those pieces in place, you should see the following message:

This is a published batch inference pipeline, which you can also see from Pipelines in the Assets menu. Batch pipelines are on the Pipeline endpoints tab in this menu.
I Need to Classify in Bulk
Kicking off a job to classify more penguin data is pretty easy. Select Submit from the batch inference pipeline to get started.

But before you hit that Submit button, we’re going to need some new data. For now, let’s Cancel and create a new dataset.
brb, Measuring Penguins
I thought about taking a trip to Antarctica and measuring some penguins to make this test real, but instead decided to take the existing penguins data, strip out the Species column, remove the two empty data points, and save it as a CSV on my local machine. Very lazy, I know. But at least it does give me the opportunity to create a new dataset for you. Navigate to the Datasets section of the Assets menu, and then choose Create dataset and From local files.

Pick a memorable name for the dataset, upload it to your blob storage account, and upload your file.

Because this is a simple file, you should be able to Next-Next-Next your way through the process and upload your file.
Now let’s return to the pipeline endpoint, select Submit once more, and choose our experiment, dataset, and dataset version.

Select Submit and watch that pipeline run, well, run. It will take a few minutes to complete, but by this point you should be very proficient at twiddling your thumbs.
Eventually, your job will finish. Select the Score Model component and scroll down in the Details section until you see Output datasets. Select the link associated with this dataset.

This takes you to the Datasets section and you can see that the process generated six files, including a Parquet file. That Parquet file contains the data you need to understand classes of penguin.

If you have Azure Synapse Analytics or Databricks, you can easily extract this data. You can also use Azure Data Factory and a host of other tools to work with it. In practice, this works out pretty well, as you’re typically using a batch endpoint because you have a lot of data, and so you’ll want to build a file retriever which grabs any relevant data files after processing is complete.
But for our demo, we just want to open up that file and view it on our PC. In that case, check out ParquetViewer. It’s an open source product which lets you view Parquet data in a GridView.

Pricing and Batch Endpoints
With real-time endpoints, we needed to have some service constantly running, waiting to accept our calls. With batch endpoints, nothing happens until you trigger the pipeline, meaning that you only need to spend money if someone (or something) kicks that pipeline off. Then, the pipeline will run using the compute target you’ve selected, so you can control how expensive the batch process is. For infrequent jobs, batch scoring can be considerably cheaper than having a Kubernetes cluster constantly running, though the advantage to the Kubernetes cluster is that you will get your results back a whole lot faster. With batch pipeline endpoints, you need to wait for the compute cluster to start up, so a 10-second scoring job might take 10 minutes because of that.
Conclusion
In this post, we looked at what it takes to create a batch inference pipeline. In the next, and final, post of the series, I’ll wrap things up.

2 thoughts on “Low-Code ML: Batch Scoring”