This is a continuation of my Polybase series.
My goal in today’s post is to insert data into Azure Blob Storage using Polybase and see what happens. My expectation is that it will behave the same as inserting into Hadoop.
Creating A New External Table
Our first step is to create a new external table. In this case, I want to store information on second basemen. I already have the data locally in a table called Player.SecondBasemen, and I’d like to move it up to Azure Blob Storage into a folder called ootp.

To do this, we’ll create a new external table:
USE [OOTP] GO CREATE EXTERNAL TABLE [dbo].[SecondBasemenWASB] ( [FirstName] [varchar](50) NULL, [LastName] [varchar](50) NULL, [Age] [int] NULL, [Throws] [varchar](5) NULL, [Bats] [varchar](5) NULL ) WITH ( DATA_SOURCE = [WASBFlights], LOCATION = N'ootp/', FILE_FORMAT = [CsvFileFormat], REJECT_TYPE = VALUE, REJECT_VALUE = 5 ) GO
Inserting Data
Inserting data is pretty easy.
INSERT INTO dbo.SecondBasemenWASB ( FirstName, LastName, Age, Throws, Bats ) SELECT sb.FirstName, sb.LastName, sb.Age, sb.Bats, sb.Throws FROM Player.SecondBasemen sb;
A few seconds later and we have some rows in the table:

We can check to make sure that everything looks fine:

I get back the same 777 results.
Looking at Azure Management Studio, I can see that the Polybase engine created a logical folder named ootp and 8 separate files, of which 4 have data.

One interesting finding is that there is also an empty block blob with the name ootp:

The timestamp for it is the same as for the initial upload, so these were created at the same time.
Uploading A Larger Data Set
I decided to take advantage of my Azure Blob Storage connection and create a larger data set. In this case, I’m going to cross join the second basemen table, creating 777 records for each of the 777 second basemen. Those will all go into Azure Blob Storage and I’ll be able to see how the Polybase engine deals with larger data sets. I’m running two tests, one which will generate 777 * 777 = 603,729 records, and one which will generate 777 * 777 * 777 = 469,097,433 records. Here’s my query for the latter:
INSERT INTO dbo.SecondBasemenWASB ( FirstName, LastName, Age, Throws, Bats ) SELECT sb.FirstName, sb.LastName, sb.Age, sb.Bats, sb.Throws FROM Player.SecondBasemen sb CROSS JOIN Player.SecondBasemen sb2 CROSS JOIN Player.SecondBasemen sb3;
Generating and uploading 600K records was pretty fast, but building 469 million records was a little slower. During this time, the Polybase engine was streaming results out, meaning it didn’t appear to write everything to a local file. The mpdwsvc service did take up about 2 GB of RAM during this time and was pushing out at about 25-30 Mbps, which is probably my Wifi connection’s limitation. All in all, it took my laptop approximately 80 minutes to generate and push those results.
The end results were not particularly shocking:
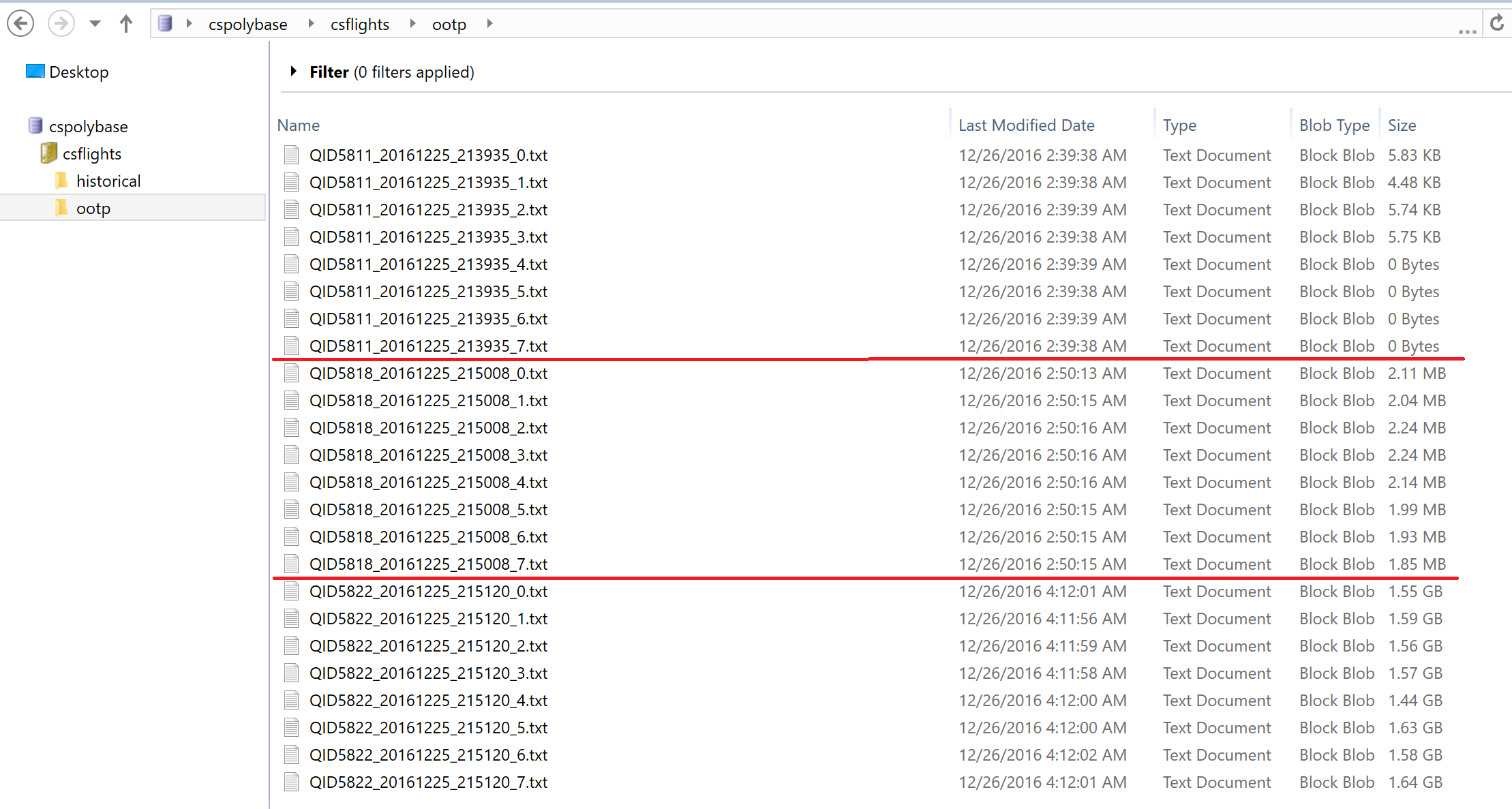
I’ve sliced the first, second, and third uploads into separate batches to make it clearer. In the first batch, as I mentioned above, only four of the files ended up with data in them. In the second batch, each file had somewhere around 2MB of write activity. For the third batch, each was about 1.5 GB. I should note that for the second run, the spread between the smallest and largest files was approximately 17.6%, whereas it was 12.3% for the third run.
What About Fixed-Width Lines?
One additional question I have involves whether the process for loading data is round-robin on a row-by-row basis. My conjecture is that it is not (particularly given that our first example had 4 files with zero records in them!), but I figured I’d create a new table and test. In this case, I’m using three fixed-width data types and loading 10 million identical records. I chose to use identical record values to make sure that the text length of the columns in this line were exactly the same; the reason is that we’re taking data out of SQL Server (where an int is stored in a 4-byte block) and converting that int to a string (where each numeric value in the int is stored as a one-byte character). I chose 10 million because I now that’s well above the cutoff point for data to go into each of the eight files, so if there’s special logic to handle tiny row counts, I’d get past it.
CREATE TABLE dbo.LocalFixed ( ID INT NOT NULL, SomeNum INT NOT NULL, SomeChar CHAR(12) NOT NULL ); INSERT INTO dbo.LocalFixed ( ID, SomeNum, SomeChar ) SELECT TOP (10000000) 1, 0, 'abcdefghijkl' FROM Player.SecondBasemen sb CROSS JOIN Player.SecondBasemen sb1 CROSS JOIN Player.SecondBasemen sb2;
From here, we can create another external table and insert our 10 million rows into it:
CREATE EXTERNAL TABLE [dbo].[RemoteFixed] ( ID INT NOT NULL, SomeNum INT NOT NULL, SomeChar CHAR(12) NOT NULL ) WITH ( DATA_SOURCE = [WASBFlights], LOCATION = N'fixed/', FILE_FORMAT = [CsvFileFormat], REJECT_TYPE = VALUE, REJECT_VALUE = 5 ); INSERT INTO dbo.RemoteFixed ( ID, SomeNum, SomeChar ) SELECT lf.ID, lf.SomeNum, lf.SomeChar FROM dbo.LocalFixed lf;
And here are the results in Blob Storage:

Even when I guarantee that rows are exactly the same size, there are still minor differences: here it’s 20.48 MB versus 20.02 MB. This indicates to me that the Polybase file write system is not round robin on a row-by-row basis, as there is a difference of 28,193 records separating the largest from the smallest file (1,262,965 rows with data in the largest file versus 1,234,772 in the smallest file).
Conclusion
Just like the Hadoop scenario, inserting into Azure Blob Storage splits the data into a set of files and uploads those files separately. There weren’t any surprises here, so you can read the Hadoop version to get the rest of the story. We did take the opportunity to learn a bit more about the way the Polybase file writer engine operates and can conclusively reject the idea that it evenly distributes records based either on data length or number of rows.
This wraps up my Polybase investigations of Azure Blob Storage for now. Next up, I’m going to look at Azure SQL Data Warehouse.

3 thoughts on “Inserting Into Azure Blob Storage”