I’m working on a new talk entitled Kafka for .NET Developers, which I plan to make part of my 2017 rotation. I’m going to give this talk first at the Triangle Area .NET User Group’s Data SIG on October 19th, so it’s about time I got started on this…
Who Is Your Broker And What Does He Do?
Apache Kafka is a message broker. Its purpose is to accept messages from one or more publishers and push messages out to one or more subscribers. It’s not an Enterprise Service Bus; it’s a stream data platform.
Maybe I just don’t have my architect hat on today, but that seems like a lot of words to describe what’s going on. I’m going to describe it my own way (with the bonus of probably getting a bunch of stuff wrong too!).
The Basics
We have an application which needs to send messages somewhere. We have a separate application which needs to consume messages from that sender. The easiest way to do that is to have the two applications directly communicate:

In this case, we have an app connecting directly to a database. For low-scale systems, this is fine. In fact, it’s better than fine: it’s easy to understand, easy to work with, and easy to fix when things go wrong.
But it has two fundamental problems: it doesn’t scale, and it doesn’t expand. If I have more users trying to connect to may app than my app server can handle, users will have to wait in line for service. Similarly, if my database cannot handle the user load my app can send, people have to wait in line.
So we decide to expand out. The easiest method of scaling out is simply to throw more app servers at the problem:

That’s cool and is also pretty easy. But what happens if our database doesn’t have the oomph to handle all of this work? Then we could scale out the databases. That looks like this:

We now have 12 separate connection points and probably some middleware to figure out when to connect what to where. Things get more complex, but you can work out some technical details and get this running fine. This can even scale out to hundreds of servers against dozens of databases. But the problem is that you need to know which database to hit. If you can guarantee this, then life is good and you can scale indefinitely. But let’s say that we don’t necessarily know which consumer should get the message. Or let’s say one of the consumers go down:

So what do we do with all of the messages that are supposed to go to that database? In our current setup, the app either holds messages until the database is back or outright fails.
Brokers
This is where a broker steps in.

The broker serves several purposes:
- Know who the producers are and who the consumers are. This way, the producers don’t care who exactly consumes a message and aren’t responsible for the message after they hand it off.
- Buffer for performance. If the consumers are a little slow at the moment but don’t usually get overwhelmed, that’s okay—messages can sit with the broker until the consumer is ready to fetch.
- Let us scale out more easily. Need to add more producers? That’s fine—tell the broker who they are. Need to add consumers? Same thing.
- What about when a consumer goes down? That’s the same as problem #2: hold their messages until they’re ready again.
So brokers add a bit of complexity, but they solve some important problems. The nice part about a broker is that it doesn’t need to know anything about the messages, only who is supposed to receive it.
Enter Kafka
Now that we have an idea of what message brokers do, let’s look at Kafka specifically.
In Kafka terms, we have producers and consumers. Producers push messages and consumers read messages. In between, we have brokers.
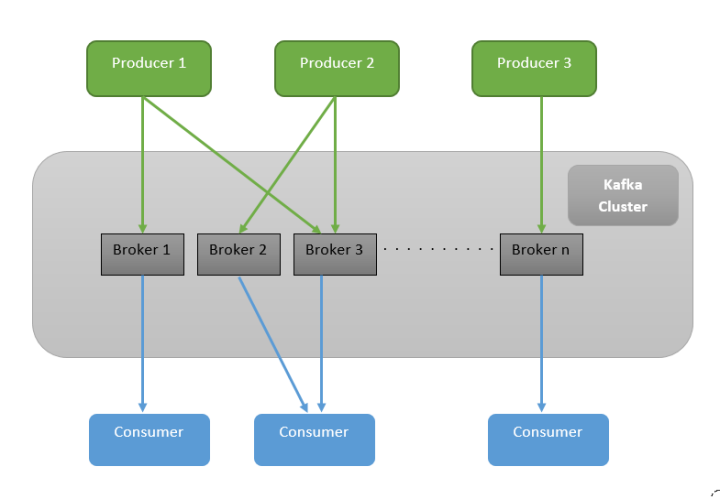
Messages belong to topics. Topics themselves are broken up into partitions. Think of an individual partition as a log. Kafka accepts messages from producers publishing to a specific topic and writes them to a partition. Consumers can read from a topic, pulling messages from one or more partitions.
Speaking of messages, it’s important to note that Kafka is not a queue. With a queue, a producer puts a message on and a consumer pops a message off. Instead, Kafka is more like a log: producers add messages and the broker keeps track of them over time. Consumers then read from the log starting at any point, which means that they’re allowed to re-read messages.
Conclusion
The purpose of this blog post was to give a basic introduction to Kafka and help understand where it fits in an architecture. Tomorrow, we’re going to look at the problem I intend to solve.
If you want more of an overview on Kafka, Kevin Sookocheff’s blog post on the topic is great.

{kind=link}
One thought on “What Is Kafka?”