Update 2016-11-08: It turns out that my yarn-site.xml configuration settings were not correct for the version of Hadoop I’m using (Hortonworks Data Platform 2.4). I have a new post which corrects this.
So, it’s been a while since I promised I would start working on a Polybase series. Life has gotten the better of me over the past few weeks, but I want to rectify that and get cracking on this Polybase series.
Installing Polybase
Edwin Sarmiento put together an installation guide during CTP2. It is still accurate. As a refresher, here are the steps:
- Install the Java Development Kit. I grab the latest version, which, because it’s Java, updates approximately 4 times a day.
- In the SQL Server installer, click the “Polybase” checkbox in the Database Engine section.
That’s a pretty short set of instructions.
Setting Up Hadoop
Polybase will allow you to connect to Azure Blob Storage or a Hadoop cluster (Hortonworks or Cloudera). I’m going to go with a Hortonworks Data Platform sandbox. I downloaded the VM and it is running on 192.168.172.149.
Once you have it running, it should look a bit like this:
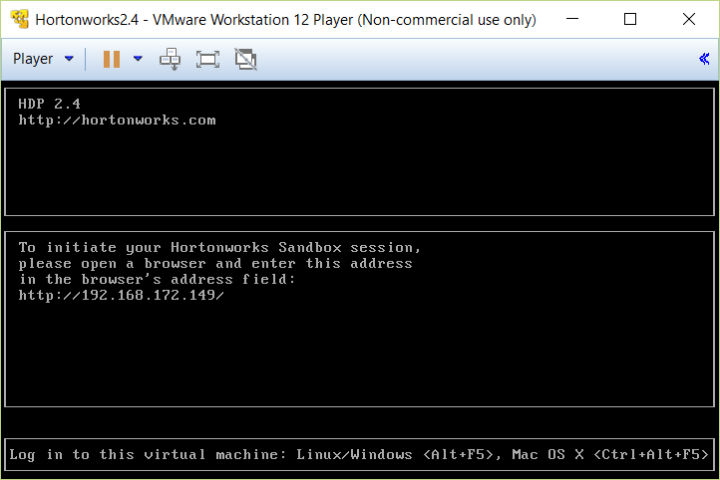
The first thing you’ll want to do is change the root password. Hit Alt+F5 to log in to the box. Note that the default username is root and password is hadoop. After you log in, you’ll be asked to change the password.

Now that we’re logged in, run the command ambari-admin-password-reset, which resets the Ambari password. Ambari is the Hortonworks management framework, and will be extremely helpful to us over the course of this series.

Once you have a reasonable password set, try logging into Ambari. It’s going to be your Hadoop sandbox IP address and port 8080, so in my case it’s http://192.168.172.149:8080. You’ll be prompted to log in, and once you do, you’ll see the Sandbox main page. It will look a bit like the following:

If everything’s green, you are good to go. Let’s keep configuring that Hadoop cluster to work with SQL Server.
Slight Sqoop Detour
We’re next going to install a JDBC driver for SQL Server. You can grab the driver from Microsoft. Follow the Hortonworks instructions except for one key point: you will need to put the driver into /usr/hdp/[version]/sqoop/lib instead of /usr/lib/sqoop/lib.
I call this a detour because, strictly speaking, you do not need the Microsoft JDBC driver for Polybase. Nevertheless, I recommend you take the couple of minutes to install this driver because you might want to play around with Sqoop later.
Configuring Polybase
Now let’s go back to SQL Server 2016 and turn on Polybase support. Run the following bit of code to ensure that you installed Polybase correctly:
SELECT SERVERPROPERTY ('IsPolybaseInstalled') AS IsPolybaseInstalled;
If you did, you’ll see it return 1 for IsPolybaseInstalled:

If that’s the case, we’ll need to set up the appropriate Hadoop cluster setting. We’re running a Hortonworks sandbox on Linux, so we’ll use option 7.
sp_configure @configname = 'hadoop connectivity', @configvalue = 7; GO RECONFIGURE GO
Microsoft’s next recommendation is to make sure that predicate pushdown is enabled. To do that, we’re going to go back to the Hadoop VM and grab our yarn.application.classpath from there. To do that, cd to /etc/hadoop/conf/ and vi yarn-site.xml (or use whatever other text reader you want). Copy the value for yarn.application.classpath, which should be a pretty long string. But beware if yours looks like the following:
<value>$HADOOP_CONF_DIR,/usr/hdp/current/hadoop-client/*,/usr/hdp/current/hadoop-client/lib/*,/usr/hdp/current/hadoop-hdfs-client/*,/usr/hdp/current/hadoop-hdfs-client/lib/*,/usr/hdp/current/hadoop-yarn-client/*,/usr/hdp/current/hadoop-yarn-client/lib/*</value>
If it does, you’ll want to read my post on configuration errors and figure out the correct connection settings.
Once you have a copy of that value, go to your SQL Server installation directory (by default, C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Binn\Polybase\Hadoop\conf) and open up yarn-site.xml. Paste the value into the corresponding yarn.application.classpath setting and that file looks good. Then, you’ll want to add the following to mapred-site.xml:
<property> <name>yarn.app.mapreduce.am.staging-dir</name> <value>/user</value> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/mr-history/done</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/mr-history/tmp</value> </property>
Once you have these configuration settings changed, you should be good to go.
Wrapup
What we’ve done today is grab and configure a Hadoop cluster and turn on Polybase. There’s still a long way to go, and in tomorrow’s blog post, I will load some quick data into Hadoop and do a quick test to ensure that I can pull data from Hadoop using Polybase. From there, we’ll start digging a bit deeper into available options and get an idea of Polybase’s true power.

Hi Kevin, thanks for this great blog! I’m working on setting up Polybase and Hadoop integration at my office. Will let you know how it goes.
Very cool. I hope it goes well for you; I’d love it if you could let me know how it goes.